In Schulen auf der ganzen Welt tippen Kinder eine Zahl in ihren LCD-Taschenrechner, drehen ihn um und lachen, nachdem sie das Wort "Boobies" erfunden haben. Natürlich ist dies das beliebteste Wort, aber es gibt viele andere Wörter, die produziert werden können.
Alle Wörter müssen jedoch kürzer als 10 Buchstaben sein (das Wörterbuch enthält jedoch Wörter, die länger sind, sodass Sie in Ihrem Programm einen Filter ausführen müssen). In diesem Wörterbuch gibt es einige Wörter in Großbuchstaben. Konvertieren Sie also alle Wörter in Kleinbuchstaben.
Erstellen Sie mit einem Wörterbuch in englischer Sprache eine Liste von Zahlen, die in einen LCD-Taschenrechner eingegeben werden können und ein Wort ergeben. Wie bei allen Code-Golf-Fragen gewinnt das kürzeste Programm, um diese Aufgabe zu erfüllen.
Für meine Tests habe ich die UNIX-Wortliste verwendet, die sich wie folgt zusammensetzt:
ln -s /usr/dict/words w.txt
Oder alternativ, bekommen sie hier .
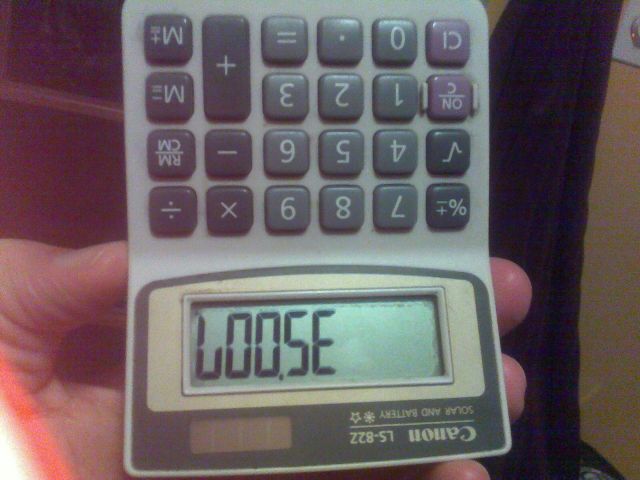
Das obige Bild wurde beispielsweise erstellt, indem die Zahl 35007in den Taschenrechner eingegeben und auf den Kopf gestellt wurde.
Die Buchstaben und ihre jeweiligen Zahlen:
- b :
8 - g :
6 - l :
7 - ich :
1 - o :
0 - s :
5 - z :
2 - h :
4 - e :
3
Beachten Sie, dass, wenn die Zahl mit einer Null beginnt, nach dieser Null ein Dezimalpunkt erforderlich ist. Die Zahl darf nicht mit einem Komma beginnen.
Ich denke das ist MartinBüttners Code, ich wollte dir das nur gutschreiben :)
/* Configuration */
var QUESTION_ID = 51871; // Obtain this from the url
// It will be like http://XYZ.stackexchange.com/questions/QUESTION_ID/... on any question page
var ANSWER_FILTER = "!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe";
/* App */
var answers = [], page = 1;
function answersUrl(index) {
return "http://api.stackexchange.com/2.2/questions/" + QUESTION_ID + "/answers?page=" + index + "&pagesize=100&order=desc&sort=creation&site=codegolf&filter=" + ANSWER_FILTER;
}
function getAnswers() {
jQuery.ajax({
url: answersUrl(page++),
method: "get",
dataType: "jsonp",
crossDomain: true,
success: function (data) {
answers.push.apply(answers, data.items);
if (data.has_more) getAnswers();
else process();
}
});
}
getAnswers();
var SIZE_REG = /\d+(?=[^\d&]*(?:<(?:s>[^&]*<\/s>|[^&]+>)[^\d&]*)*$)/;
var NUMBER_REG = /\d+/;
var LANGUAGE_REG = /^#*\s*([^,]+)/;
function shouldHaveHeading(a) {
var pass = false;
var lines = a.body_markdown.split("\n");
try {
pass |= /^#/.test(a.body_markdown);
pass |= ["-", "="]
.indexOf(lines[1][0]) > -1;
pass &= LANGUAGE_REG.test(a.body_markdown);
} catch (ex) {}
return pass;
}
function shouldHaveScore(a) {
var pass = false;
try {
pass |= SIZE_REG.test(a.body_markdown.split("\n")[0]);
} catch (ex) {}
return pass;
}
function getAuthorName(a) {
return a.owner.display_name;
}
function process() {
answers = answers.filter(shouldHaveScore)
.filter(shouldHaveHeading);
answers.sort(function (a, b) {
var aB = +(a.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0],
bB = +(b.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0];
return aB - bB
});
var languages = {};
var place = 1;
var lastSize = null;
var lastPlace = 1;
answers.forEach(function (a) {
var headline = a.body_markdown.split("\n")[0];
//console.log(a);
var answer = jQuery("#answer-template").html();
var num = headline.match(NUMBER_REG)[0];
var size = (headline.match(SIZE_REG)||[0])[0];
var language = headline.match(LANGUAGE_REG)[1];
var user = getAuthorName(a);
if (size != lastSize)
lastPlace = place;
lastSize = size;
++place;
answer = answer.replace("{{PLACE}}", lastPlace + ".")
.replace("{{NAME}}", user)
.replace("{{LANGUAGE}}", language)
.replace("{{SIZE}}", size)
.replace("{{LINK}}", a.share_link);
answer = jQuery(answer)
jQuery("#answers").append(answer);
languages[language] = languages[language] || {lang: language, user: user, size: size, link: a.share_link};
});
var langs = [];
for (var lang in languages)
if (languages.hasOwnProperty(lang))
langs.push(languages[lang]);
langs.sort(function (a, b) {
if (a.lang > b.lang) return 1;
if (a.lang < b.lang) return -1;
return 0;
});
for (var i = 0; i < langs.length; ++i)
{
var language = jQuery("#language-template").html();
var lang = langs[i];
language = language.replace("{{LANGUAGE}}", lang.lang)
.replace("{{NAME}}", lang.user)
.replace("{{SIZE}}", lang.size)
.replace("{{LINK}}", lang.link);
language = jQuery(language);
jQuery("#languages").append(language);
}
}body { text-align: left !important}
#answer-list {
padding: 10px;
width: 50%;
float: left;
}
#language-list {
padding: 10px;
width: 50%px;
float: left;
}
table thead {
font-weight: bold;
}
table td {
padding: 5px;
}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<link rel="stylesheet" type="text/css" href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b">
<div id="answer-list">
<h2>Leaderboard</h2>
<table class="answer-list">
<thead>
<tr><td></td><td>Author</td><td>Language</td><td>Size</td></tr>
</thead>
<tbody id="answers">
</tbody>
</table>
</div>
<div id="language-list">
<h2>Winners by Language</h2>
<table class="language-list">
<thead>
<tr><td>Language</td><td>User</td><td>Score</td></tr>
</thead>
<tbody id="languages">
</tbody>
</table>
</div>
<table style="display: none">
<tbody id="answer-template">
<tr><td>{{PLACE}}</td><td>{{NAME}}</td><td>{{LANGUAGE}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
<table style="display: none">
<tbody id="language-template">
<tr><td>{{LANGUAGE}}</td><td>{{NAME}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
0.7734für hallo tippen oder wäre.7734das akzeptabel?0.7734ist erforderlicholigoerfordert eine Hinter Null nach dem Komma:0.6170Antworten:
CJam,
4442 BytesProbieren Sie es online im CJam-Interpreter aus .
Laden Sie den Java-Interpreter herunter und führen Sie Folgendes aus, um das Programm über die Befehlszeile auszuführen:
Wie es funktioniert
quelle
Bash + Coreutils, 54
Nochmals vielen Dank an @TobySpeight für die Golfhilfe.
Die eingegebene Wortliste stammt aus STDIN:
quelle
Python 2,
271216211205 BytesDies ist die einzige Idee, die ich bisher hatte. Ich werde sie aktualisieren, sobald mir etwas anderes einfällt! Ich nahm an, wir müssten aus einer Datei lesen, aber wenn nicht, lass es mich wissen, damit ich updaten kann :)
Vielen Dank an Dennis, der mir 55 Bytes gespart hat :)
Danke auch an Sp3000 für das Speichern von 6 Bytes :)
quelle
"oizehsglb".index(b)nicht kürzer sein?d[b] == "oizehsglb".index(b). Möglicherweise fehlt eine Besetzung für Zeichenfolge / Charakter..findist kürzer als.index, 2) Abhängig von der Version, die Sie haben, mindestens in 2.7.10openohne ein Standardargument für den Modusr, 3) funktioniert nicht nurfor x in open(...)? (Möglicherweise muss eine nachgestellte Zeile entfernt werden.) Ist dies nicht der Fall,.split('\n')ist sie kürzer als.splitlines()g+=[['0.'+c[1:],c][c[0]!='0']]*c.isdigit(), und Sie können durch Umkehren in ein paar mehr sparenfdann tunfor c in fstatt mitc=x[::-1]. Auch Sie nurfeinmal verwenden, so müssen Sie es nicht als VariableJavaScript (ES7), 73 Byte
Dies ist in ES7 in nur 73 Bytes möglich:
Ungolfed:
Verwendung:
Funktion:
Ich habe dies auf der UNIX-Wortliste ausgeführt und die Ergebnisse in einen Einfügebehälter gestellt:
Ergebnisse
Der Code, mit dem die Ergebnisse in Firefox abgerufen werden :
quelle
t('Impossible')?Python 2, 121 Bytes
Es wird davon
w.txtausgegangen, dass die Wörterbuchdatei mit einem nachgestellten Zeilenumbruch endet und keine leeren Zeilen enthält.quelle
GNU sed, 82
(einschließlich 1 für
-r)Vielen Dank an @TobySpeight für die Golfhilfe.
Die eingegebene Wortliste stammt aus STDIN:
quelle
TI-BASIC,
7588 Bytesedit 2: egal, das ist technisch immer noch ungültig, da es immer nur ein wort akzeptiert (kein wörterbuch). Ich werde versuchen, es zu reparieren, um mehr als ein Wort als Eingabe zuzulassen ...
bearbeiten: oops; Ich ließ es ursprünglich am Ende eine .0 anzeigen, wenn die letzte Zahl 0 war, nicht umgekehrt. Behoben, obwohl dies eine schlechte Problemumgehung ist (zeigt "0" neben der Zahl an, wenn sie mit 0 beginnt, andernfalls werden zwei Leerzeichen an derselben Stelle angezeigt). Auf der hellen Seite werden Wörter wie "Otto" (zeigt beide Nullen an) richtig behandelt, da keine Dezimalzahl angezeigt wird!
Ich kann mir keine bessere Sprache dafür vorstellen. Kann definitiv mehr Golf spielen, aber ich bin im Moment zu müde. Die Tilde ist das Negationssymbol [der ( - )Knopf].
Die Eingabe erfolgt über die Antwortvariable des Rechners. Dies bedeutet, was auch immer zuletzt ausgewertet wurde (wie
_in der interaktiven Python-Shell). Sie müssen also eine Zeichenfolge auf dem Startbildschirm eingeben (Anführungszeichen ist aktiviert ALPHA+), drücken ENTERund das Programm ausführen. Alternativ können Sie einen Doppelpunkt verwenden, um Befehle zu trennen. Wenn Sie das Programm also "CALCTEXT" nennen und es in der Zeichenfolge "HELLO" ausführen möchten, können Sie eingeben,"HELLO":prgmCALCTEXTanstatt sie separat auszuführen .quelle
Python 2,
147158156 BytesMir hat diese 0 gefehlt. Anforderung. Hoffe jetzt klappt es in Ordnung.
edit : ".readlines ()" entfernt und es funktioniert immer noch; p
edit2 : Einige Leerzeichen wurden entfernt und der Ausdruck in die 3. Zeile verschoben
edit3 : 2 Bytes dank Sp3000 gespeichert (Leerzeichen nach dem Drucken entfernt und 'index' in 'find' geändert)
quelle
Python 2,
184174 Bytesquelle
Ruby 2,
8886 BytesDie Byteanzahl umfasst 2 für die
lnOptionen in der Befehlszeile:quelle
==""kann durch ersetzt werden<?A. Und keine Notwendigkeit fürgsub()sosub()ist genug.C
182172169/181172 BytesErweitert
Verwenden der verknüpften Datei words.txt mit Konvertierung in Kleinbuchstaben:
quelle
*s|32als Kleine Umwandlung in diesem Zusammenhang arbeiten?Haskell, 175 Bytes ohne Importe (229 Bytes mit Importen)
Relevanter Code (z. B. in Datei Calc.hs):
quelle
Java,
208200176 BytesErweitert
Es wird immer die Dezimalstelle hinzugefügt, und wenn ungültig, wird "." Zurückgegeben. Funktioniert aber sonst so wie es soll. : P
Vielen Dank an LegionMammal978!
quelle
;String l=zu,l=und=o+zu wechseln+=.