Der Räuberherausforderungs-Thread ist da .
Die Herausforderung von Cops: Entwerfen Sie eine Programmiersprache, die für die Programmierung unbrauchbar zu sein scheint, aber die Berechnung (oder zumindest den Abschluss der Aufgabe) über einen nicht offensichtlichen Mechanismus zulässt.
Sie sollten eine einfache Programmiersprache entwerfen, die Code aus einer Eingabedatei liest und dann ... etwas unternimmt. Sie müssen ein Lösungsprogramm vorbereiten , das die drittgrößte Zahl in der Eingabe findet, wenn es in Ihrem Interpreter ausgeführt wird. Sie müssen es den Räubern so schwer wie möglich machen, ein Lösungsprogramm zu finden. Beachten Sie, dass Räuber jede Lösung posten können , die die Aufgabe erfüllt, und nicht nur die, die Sie sich vorgestellt haben.
Dies ist ein Beliebtheitswettbewerb. Das Ziel der Polizei ist es, so viele Stimmen wie möglich zu erhalten, während sie 8 Tage nach dem Absenden des Dolmetschers überlebt, ohne geknackt zu werden. Zu diesem Zweck sollten die folgenden Vorgehensweisen hilfreich sein:
- Erklären Sie genau die Semantik Ihrer Sprache
- Lesbaren Code schreiben
Von folgenden Taktiken wird dringend abgeraten:
- Verwenden von Verschlüsselung, Hashes oder anderen kryptografischen Methoden. Wenn Sie eine Sprache sehen, die RSA-Verschlüsselung verwendet, oder die Ausführung eines Programms verweigert, es sei denn, der SHA-3-Hash ist gleich 0x1936206392306, zögern Sie nicht, eine Ablehnung vorzunehmen.
Die Herausforderung von Robbers: Schreiben Sie ein Programm, das die drittgrößte Ganzzahl in der Eingabe findet, wenn es im Interpreter der Polizei ausgeführt wird.
Dieser ist relativ einfach. Um eine Cop-Antwort zu knacken, müssen Sie ein Programm erstellen, das die Aufgabe abschließt, wenn es in seinem Interpreter ausgeführt wird. Wenn Sie eine Antwort knacken, geben Sie in der Antwort des Polizisten, die mit Ihrem Beitrag verknüpft ist, einen Kommentar mit der Aufschrift "Geknackt" ein. Wer die meisten Bullen knackt, gewinnt den Raubfaden.
E / A-Regeln
- Dolmetscher sollten in der Befehlszeile einen Dateinamen für das Programm verwenden und beim Ausführen die Standardeingabe und -ausgabe verwenden.
- Die Eingabe erfolgt unär und besteht nur aus den Zeichen
0und1(48 und 49 in ASCII). Eine Zahl N wird als N1sgefolgt von a codiert0. Es gibt eine zusätzliche0vor dem Ende der Datei. Beispiel: Für die Sequenz (3, 3, 1, 14) lautet die Eingabe11101110101111111111111100. - Die Eingabe hat garantiert mindestens 3 Zahlen. Alle Zahlen sind positive ganze Zahlen.
- Die Ausgabe wird anhand der Anzahl der
1gedruckten Sekunden beurteilt, bevor das Programm angehalten wird. Andere Zeichen werden ignoriert.
In den folgenden Beispielen ist die erste Zeile die Eingabe im Dezimalformat. die zweite ist die tatsächliche Programmeingabe; Die dritte ist eine Beispielausgabe.
1, 1, 3
101011100
1
15, 18, 7, 2, 15, 12, 3, 1, 7, 17, 2, 13, 6, 8, 17, 7, 15, 11, 17, 2
111111111111111011111111111111111101111111011011111111111111101111111111110111010111111101111111111111111101101111111111111011111101111111101111111111111111101111111011111111111111101111111111101111111111111111101100
111111,ir23j11111111111u
247, 367, 863, 773, 808, 614, 2
<omitted>
<contains 773 1's>
Langweilige Regeln für Cop Antworten:
- Um Sicherheit durch Unklarheit zu verhindern, sollte der Interpreter in einer Sprache geschrieben sein, die in den Top 100 dieses TIOBE-Index steht, und über einen frei verfügbaren Compiler / Interpreter verfügen.
- Der Dolmetscher darf keine Sprache interpretieren, die vor dieser Aufforderung veröffentlicht wurde.
- Der Dolmetscher sollte in Ihre Stelle passen und nicht extern gehostet werden.
- Der Dolmetscher sollte deterministisch sein
- Der Dolmetscher sollte tragbar sein und dem Standard seiner eigenen Sprache folgen. Verwenden Sie keine undefinierten Verhaltensweisen oder Fehler
- Wenn das Lösungsprogramm zu lang ist, um in die Antwort zu passen, müssen Sie ein Programm veröffentlichen, das es generiert.
- Das Lösungsprogramm sollte nur aus druckbarem ASCII und Zeilenumbrüchen bestehen.
- Sie müssen Ihr Lösungsprogramm für jede der obigen Beispieleingaben in weniger als 1 Stunde auf Ihrem eigenen Computer ausführen.
- Das Programm sollte für Ganzzahlen unter 10 6 und für eine beliebige Anzahl von Ganzzahlen unter 10 6 (nicht unbedingt in weniger als einer Stunde) funktionieren , vorausgesetzt, die Gesamteingabelänge beträgt weniger als 10 9 .
- Um sicher zu gehen, muss ein Polizist das Lösungsprogramm nach Ablauf von 8 Tagen in der Antwort bearbeiten.
Wertung
Der Cop, der mit der höchsten Punktzahl und einer positiven Punktzahl in Sicherheit ist, gewinnt diese Frage.
Antworten:
Changeling (sicher)
ShapeScript
ShapeScript ist eine natürlich vorkommende Programmiersprache. Shape Shifter (oder Changelings , wie sie am liebsten genannt werden) können in eine Reihe von Anweisungen umgewandelt werden, mit denen sie Daten verarbeiten können.
ShapeScript ist eine stapelbasierte Sprache mit einer relativ einfachen Syntax. Es ist nicht verwunderlich, dass sich die meisten der integrierten Funktionen mit der Änderung der Form von Saiten befassen. Es wird zeichenweise wie folgt interpretiert:
'und"beginne ein String-Literal.Bis das übereinstimmende Zitat im Quellcode gefunden wird, werden alle Zeichen zwischen diesen übereinstimmenden Zitate in einer Zeichenfolge gesammelt, die dann auf den Stapel verschoben wird.
09um die ganzen Zahlen 0 bis 9 auf den Stapel zu schieben . Beachten Sie, dass10schiebt zwei ganzen Zahlen.!Fügt eine Zeichenfolge aus dem Stapel hinzu und versucht, sie als ShapeScript auszuwerten.?Fügt eine Ganzzahl aus dem Stapel hinzu und legt eine Kopie des Stapelelements an diesem Index ab.Index 0 entspricht dem obersten Stapelelement (LIFO) und Index -1 dem untersten.
_Entfernt ein Iterationsobjekt aus dem Stapel und verschiebt seine Länge.@Löst zwei Elemente aus dem Stapel und verschiebt sie in umgekehrter Reihenfolge.$Löst zwei Zeichenfolgen aus dem Stapel und teilt die unterste Zeichenfolge bei Auftreten der obersten Zeichenfolge auf. Die resultierende Liste wird zurückgeschoben.&Fügt eine Zeichenfolge (ganz oben) und ein Iterationszeichen aus dem Stapel hinzu und fügt das Iterationszeichen hinzu, wobei die Zeichenfolge als Trennzeichen verwendet wird. Die resultierende Zeichenfolge wird zurückgegeben.Wenn ShapeScript auf unserem Planeten verwendet wird, da Pythons die Wechselbälger engsten Verwandten auf der Erde sind, alle anderen Zeichen c zwei Artikel Pop - x und y (oberste) vom Stapel, und versuchen , den Python - Code zu bewerten
x c y.Beispielsweise
23+würde die Zeichenfolge ausgewertet2+3, während die Zeichenfolge"one"3*ausgewertet'one'*3und die Zeichenfolge1''Aausgewertet würde1A''.Im letzten Fall würde sich der Changeling beschweren, da das Ergebnis kein gültiges Python ist, da es kein gültiges ShapeScript ist (Syntaxfehler).
Vor dem Ausführen des Codes legt der Interpreter die gesamte Benutzereingabe in Form einer Zeichenfolge auf dem Stapel ab. Nach dem Ausführen des Quellcodes druckt der Interpreter alle Elemente auf dem Stapel. Wenn ein Teil dazwischen ausfällt, wird der Changeling beschweren, dass seine aktuelle Form unangemessen ist (Laufzeitfehler).
Formänderung
In ihrem natürlichen Zustand haben Änderungen nicht die Form von ShapeScript. Einige von ihnen können sich jedoch in einen potenziellen Quellcode verwandeln (was nicht unbedingt nützlich oder sogar syntaktisch gültig ist).
Alle berechtigten Änderungen haben die folgende natürliche Form:
Alle Zeilen müssen die gleiche Anzahl von Zeichen haben.
Alle Zeilen müssen aus druckbaren ASCII-Zeichen bestehen, gefolgt von einem einzelnen Zeilenvorschub.
Die Anzahl der Zeilen muss mit der Anzahl der druckbaren Zeichen pro Zeile übereinstimmen.
Beispielsweise ist die Bytesequenz
ab\ncd\neine zulässige Änderung.Bei dem Versuch, in ShapeScript zu wechseln, wird das Changeling wie folgt transformiert:
Anfangs gibt es keinen Quellcode.
Für jede Zeile passiert folgendes:
Der Akkumulator des Changeling wird auf Null gesetzt.
Für jedes Zeichen c der Zeile (einschließlich des nachfolgenden Zeilenvorschubs) wird der Codepunkt von c mit dem durch 2 geteilten Akkumulator XOR-verknüpft, und das Unicode-Zeichen, das dem resultierenden Codepunkt entspricht, wird an den Quellcode angehängt.
Danach wird die Differenz zwischen dem Codepunkt von c und dem Codepunkt eines Leerzeichens (32) zum Akkumulator addiert.
Wenn ein Teil des oben genannten fehlschlägt, wird der Changeling sich darüber beklagen, dass seine aktuelle Form unangenehm ist.
Nachdem alle Zeilen verarbeitet wurden, ist die Umwandlung von Changeling in (hoffentlich gültiges) ShapeScript abgeschlossen und der resultierende Code wird ausgeführt.
Lösung (ShapeScript)
ShapeScript erwies sich tatsächlich als recht brauchbar. es kann sogar Primalitätstests ( Beweise ) durchführen und erfüllt daher unsere Definition der Programmiersprache.
Ich habe ShapeScript auf GitHub neu veröffentlicht , mit einer leicht geänderten Syntax und besseren E / A.
Der Code bewirkt Folgendes:
Lösung (Changeling)
Wie alle Changeling-Programme verfügt dieser Code über einen nachgestellten Zeilenvorschub.
ShapeScript wird Fehler sofort auf jedes Zeichen nicht verstehen, aber wir können beliebige Zeichenfolgen als Füllstoffe drücken und sie später einfügen. Dies ermöglicht es uns, nur eine kleine Menge Code in jede Zeile zu schreiben (am Anfang, wo der Akku klein ist), gefolgt von einer Öffnung
". Wenn wir die nächste Zeile mit beginnen"#, schließen wir den String und fügen ihn ein, ohne den eigentlichen Code zu beeinflussen.Außerdem müssen wir drei kleine Hindernisse überwinden:
Die lange Zeichenfolge im ShapeScript-Code ist ein einzelnes Token und kann nicht in eine Zeile eingefügt werden.
Wir werden diesen String in Chunks (
'@','1?'usw.) verschieben, die wir später verketten werden.Der Codepunkt von
_ist ziemlich hoch und das Drücken'_'wird problematisch sein.Wir können jedoch
'_@'mühelos pushen , gefolgt von einem anderen'@', um den Swap rückgängig zu machen.Der ShapeScript Code unserer Wechselbalg wird wie folgt aussieht erzeugen 1 :
Ich habe den Changeling-Code gefunden, indem ich den obigen ShapeScript-Code über diesen Konverter ausgeführt habe . 2
Dolmetscher (Python 3)
1 Jede Zeile wird mit Zufallsmüll auf die Anzahl der Zeilen aufgefüllt, und die Zeilenvorschübe sind tatsächlich nicht vorhanden.
2 Die Zahlen unten geben den niedrigsten und höchsten Codepunkt im Changeling-Code an, der zwischen 32 und 126 liegen muss.
quelle
0"#002?'+'&'0'$'0?2?-@2?>*+00'&!++'1'*'0'+@1?$0?''&@_2-2?*@+@"3*!@#. Ich habe es jedoch aufgegeben, einen Changeling dafür zu finden. Selbst wenn ich mit zumeist nutzlosen Aussagen durchsetzt bin, konnte ich nicht mehr als 20 BytesShuffle (geschrieben in C ++), Cracked! von Martin
Edit Martin hat es geknackt. Klicken Sie auf den Link, um seine Lösung anzuzeigen. Meine Lösung wurde ebenfalls hinzugefügt.
Edit Fixed-
print-dBefehl, um sowohl Register als auch Stapel verarbeiten zu können. Da dies ein Debugging-Befehl ist, der in einer Lösung nicht zulässig ist, sollte dies niemanden betreffen, der die vorherige Version des Interpreters verwendetIch bin noch neu in diesem Bereich. Wenn also etwas mit meiner Antwort oder meinem Dolmetscher nicht stimmt, lassen Sie es mich bitte wissen. Bitte fragen Sie nach einer Klärung, wenn etwas nicht klar ist.
Ich kann mir nicht vorstellen, dass dies zu schwierig sein wird, aber ich hoffe, dass es eine Herausforderung sein wird. Was Shuffle ziemlich unbrauchbar macht, ist, dass es nur gedruckt wird, wenn sich die Dinge an ihrem richtigen Ort befinden.
-> Grundlagen:
Es gibt 24 Stapel, wir nennen sie
stack1, ... stack24. Diese Stapel leben in einer Liste. Zu Beginn eines Programms haben diese Stapel den Wert Null und beginnen an der richtigen Stelle, dh Stapel i an der i-ten Position in der Liste (Beachten Sie, dass wir im Gegensatz zu C ++ ab 1 indexieren). Während eines Programmablaufs ändert sich die Reihenfolge der Stapel in der Liste. Dies ist aus Gründen wichtig, die im Zusammenhang mit den Befehlen erläutert werden.Es stehen 5 Register zur Verfügung. Sie sind benannt
Alberto,Gertrude,Hans,Leopold,ShabbySam. Jedes von diesen wird zu Beginn eines Programms auf Null gesetzt.Zu Beginn eines Programms gibt es also 24 Stapel, von denen jeder eine Nummer hat, die seinem Index in der Stapelliste entspricht. Jeder Stapel hat genau eine Null oben. Jedes der fünf Register wird auf Null initialisiert.
-> Befehle und Syntax :
Es gibt 13 Befehle (+1 Debugging-Befehl), die in Shuffle verfügbar sind. Sie sind wie folgt
cinpushDieser Befehl akzeptiert keine Argumente. Es wartet auf die in der Frage beschriebene Eingabe in der Befehlszeile (andere Eingaben führen zu nicht festgelegten / undefinierten Ergebnissen). Anschließend teilt die Eingabezeichenfolge in ganzen Zahlen, zum Beispiel101011100->1,1,3. Für jede empfangene Eingabe wird Folgendes ausgeführt: (1) Die Liste der Stapel wird basierend auf dem Wert permutiert. Der betreffende ganzzahlige Wert sei a . Wenn a kleiner als 10 ist, erfolgt die Permutation u . Wenn a zwischen 9 und 30 liegt (nicht einschließend), wird Permutation d ausgeführt . Ansonsten macht es die Permutation r . (2) Es drückt dann aauf den Stapel, der an erster Stelle in der Liste steht. Beachten Sie, dass ich das nicht meinestack1(obwohl es der Fall sein kann, der anstack1erster Stelle in der Liste steht). Die Permutationen sind unten definiert. Da diescinpushder einzige Weg ist, Benutzereingaben zu erhalten , müssen diese in jeder Lösung erscheinen.mov value registerDermovBefehl ist im Grunde eine variable Zuweisung. Es weistvaluezuregister.valuekann verschiedene Formen annehmen: Es kann (1) eine Ganzzahl sein, zB47(2) der Name eines anderen Registers, zBHans(3) der Index eines Stapels gefolgt von 's', zB4s. Beachten Sie, dass dies der Index in der Liste ist, nicht die Nummer des Stapels. Daher sollte die Anzahl 24 nicht überschreiten.Einige
movBeispiele:movfs index registerDies steht für "Move from Stack". Es ist demmovBefehl ähnlich . Es ist vorhanden, damit Sie auf einen durch ein Register indizierten Stapel zugreifen können. Wenn Sie beispielsweise zuvor Hans auf 4 (mov 4 Hans) gesetzt haben, können Siemovfs Hans GertrudeGertrude mit auf den Anfang von Stapel 4 setzen. Auf diese Art von Verhalten kann nicht einfach mit zugegriffen werdenmov.inc registerErhöht den Registerwert um 1.dec registerverringert den Registerwert um 1.compg value value registerDies steht für "größer vergleichen". Es setzt das Register gleich dem größeren der beiden Werte.valuekann eine Ganzzahl, ein Register oder ein Stapelindex sein, gefolgt von 's', wie oben.compl value value register'compare lesser' wie oben, außer dass der kleinere Wert verwendet wird.gte value1 value2 registerPrüft, obvalue1 >= value2dann der Boolesche Wert (als 1 oder 0) eingegeben wirdregister.POP!! indexEntfernt sich vom oberen Rand des Stapels, derindexin der Stapelliste durch gekennzeichnet ist.jmp labelspringt bedingungslos zum Etikettlabel. Dies ist ein guter Zeitpunkt, um über Labels zu sprechen. Ein Label ist ein Wort gefolgt von ':'. Der Interpreter parst Labels vor, sodass Sie sowohl vorwärts als auch rückwärts zu Labels springen können.jz value labelspringt zulabelwennvalueNull ist.jnz value labelspringt zulabelwennvalueungleich Null ist.Beispiele für Beschriftungen und Springen:
"shuffle" permutationHier ist der Shuffle-Befehl. Auf diese Weise können Sie die Liste der Stapel verschieben. Es gibt drei gültige Permutationen , die als Argumente verwendet werden könnenl,fundb.print registerDies prüft, ob sich alle Stapel in ihrer Anfangsposition befinden, dh der Stapel i befindet sich am Index i in der Stapelliste. Wenn dies der Fall ist, wird der Wert mitregisterunär ausgegeben. Andernfalls wird ein böser Fehler ausgegeben. Wie Sie sehen, müssen sich alle Stapel an den richtigen Stellen befinden, um etwas auszugeben.done!Dies weist das Programm an, ohne Fehler zu beenden. Wenn das Programm ohne beendetdone!wird, druckt es die Nummer über jedem Stapel, gefolgt von der Nummer des Stapels, auf die Konsole. Die Reihenfolge, in der die Stapel gedruckt werden, ist die Reihenfolge, in der sie in der Stapelliste angezeigt werden. Wenn ein Stapel leer ist, wird er weggelassen. Dieses Verhalten dient zum Debuggen und kann möglicherweise nicht in einer Lösung verwendet werden.print-d valueDies gibt den Wert des angegebenen Stapels, Registers oder der angegebenen Ganzzahl aus (um auf den Stapel i zuzugreifen , übergeben Sie ihnisals Argument, wie oben erläutert). Dies ist ein Debugging-Tool und nicht Teil der Sprache, da dies in einer Lösung nicht zulässig ist.-> Hier ist der Interpretercode
Das gesamte Parsen findet in der Hauptfunktion statt. Hier finden Sie das Parsen für bestimmte Befehle.
-> Permutationen Die Permutationen durchdringen die Elemente der Stapelliste auf folgende Weise:
Wo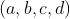 bedeutet das?
bedeutet das?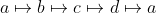
(Diese werden auch im Interpretercode angezeigt. Wenn eine Diskrepanz besteht, ist der Interpreter korrekt.)
-> Einfaches Beispiel
Diese beiden einfachen Programme geben die Zahlen von 24 bis 1 (in unary) ohne Leerzeichen aus.
oder
Sie sind das gleiche Programm.
Erklärung und Lösung:
Martin hat auch eine gute Erklärung in seiner Antwort .
Wie Martin herausfand, wurde diese Sprache vom Pocket Cube (auch bekannt als 2x2 Rubik's Cube) inspiriert. Die 24 Stapel sind wie die 24 einzelnen Quadrate auf dem Würfel. Die Permutationen sind die erlaubten Grundbewegungen: hoch, runter, rechts, links, vorne, hinten.
Der Hauptkampf besteht darin, dass beim Drücken von Werten nur drei Züge ausgeführt werden: hoch, runter und rechts. Sie haben jedoch keinen Zugriff auf diese Züge, wenn Sie die Stapel "mischen". Sie haben nur die anderen drei Züge.
Wie sich herausstellt, erstrecken sich beide Sätze von drei Zügen tatsächlich über die gesamte Gruppe (dh sind Generatoren), sodass das Problem lösbar ist. Das bedeutet, dass Sie einen beliebigen 2x2 Rubik-Würfel nur mit 3 Zügen lösen können.
Alles, was Sie tun müssen, ist herauszufinden, wie Sie die Bewegungen nach oben, unten und rechts mithilfe der anderen drei rückgängig machen können. Zu diesem Zweck habe ich ein Computeralgebrasystem namens GAP eingesetzt .
Nachdem Sie die Permutationen rückgängig gemacht haben, ist es ziemlich trivial, die drittgrößte Zahl zu finden.
quelle
Brian & Chuck , Gebrochen von cardboard_box
Ich bin schon seit einiger Zeit von der Idee einer Programmiersprache fasziniert, in der zwei Programme miteinander interagieren (wahrscheinlich inspiriert von ROCB ). Diese Herausforderung war ein guter Anreiz, dieses Konzept endlich in Angriff zu nehmen und gleichzeitig die Sprache so gering wie möglich zu halten. Die Entwurfsziele waren, die Sprache Turing-vollständig zu machen, während jedes seiner Teile einzeln nicht Turing-vollständig ist. Darüber hinaus sollten auch beide zusammen nicht vollständig sein, ohne den Quellcode zu manipulieren. Ich glaube, das ist mir gelungen, aber ich habe noch keines dieser Dinge formal bewiesen. Also präsentiere ich Ihnen ohne weiteres ...
Die Protagonisten
Brian und Chuck sind zwei Brainfuck-ähnliche Programme. Es wird immer nur einer hingerichtet, beginnend mit Brian. Der Haken ist, dass Brians Memory Tape auch Chucks Quellcode ist. Und Chucks Memory Tape ist auch Brians Quellcode. Außerdem ist Brians Tonkopf auch Chucks Anweisungszeiger und umgekehrt. Die Bänder sind semi-infinite (dh unendlich rechts) und können vorzeichenbehaftete Ganzzahlen mit willkürlicher Genauigkeit enthalten, die mit Null initialisiert sind (sofern im Quellcode nichts anderes angegeben ist).
Da der Quellcode auch ein Speicherband ist, werden Befehle technisch durch ganzzahlige Werte definiert, sie entsprechen jedoch sinnvollen Zeichen. Die folgenden Befehle sind vorhanden:
,(44): Liest ein Byte von STDIN in die aktuelle Speicherzelle. Das kann nur Brian. Dieser Befehl ist ein No-Op für Chuck..(46): Schreibe die aktuelle Speicherzelle, Modulo 256, als Byte nach STDOUT. Das kann nur Chuck. Dieser Befehl ist ein No-Op für Brian.+(43): Erhöht die aktuelle Speicherzelle.-(45): Dekrementiert die aktuelle Speicherzelle.?(63): Wenn die aktuelle Speicherzelle Null ist, ist dies ein No-Op. Andernfalls übergeben Sie die Steuerung an das andere Programm. Der Bandkopf des verwendeten Programms?verbleibt auf der?. Der Bandkopf des anderen Programms verschiebt eine Zelle nach rechts, bevor der erste Befehl ausgeführt wird (die als Test verwendete Zelle wird also nicht selbst ausgeführt).<(60): Bewegen Sie den Bandkopf eine Zelle nach links. Dies ist ein No-Op, wenn sich der Bandkopf bereits am linken Ende des Bandes befindet.>(62): Bewegen Sie den Bandkopf eine Zelle nach rechts.{(123): Bewegen Sie den Bandkopf wiederholt nach links, bis entweder die aktuelle Zelle Null ist oder das linke Ende des Bandes erreicht ist.}(125): Bewegen Sie den Bandkopf wiederholt nach rechts, bis die aktuelle Zelle Null ist.Das Programm wird beendet, wenn der Befehlszeiger des aktiven Programms einen Punkt erreicht, an dem rechts von ihm keine Befehle mehr vorhanden sind.
Der Quellcode
Die Quelldatei wird wie folgt verarbeitet:
```, wird die Datei um das erste Vorkommen dieser Zeichenfolge in zwei Teile aufgeteilt. Alle führenden und nachfolgenden Leerzeichen werden entfernt und der erste Teil wird als Quellcode für Brian und der zweite Teil für Chuck verwendet._in beiden Programmen werden durch NULL-Bytes ersetzt.Als Beispiel die folgende Quelldatei
Würde die folgenden anfänglichen Bänder ergeben:
Der Dolmetscher
Der Interpreter ist in Ruby geschrieben. Es dauert zwei Kommandozeilen - Flags , die müssen nicht von einer Lösung verwendet werden (da sie nicht Teil der eigentlichen Sprachspezifikation sind):
-d: Mit dieser Flagge verstehen Brian und Chuck zwei weitere Befehle.!druckt eine Zeichenfolgendarstellung beider Speicherbänder, wobei das aktive Programm zuerst aufgelistet wird (a^markiert die aktuellen Bandköpfe).@werde das auch machen, dann aber sofort das programm beenden. Da ich faul bin, funktioniert keiner dieser Befehle, wenn es sich um den letzten Befehl im Programm handelt. Wenn Sie sie dort verwenden möchten, wiederholen Sie sie oder schreiben Sie ein No-Op nach ihnen.-D: Dies ist der ausführliche Debug-Modus. Es werden die gleichen Debug-Informationen wie!nach jedem einzelnen Tick ausgegeben.@funktioniert auch in diesem Modus.Hier ist der Code:
Hier ist meine eigene (handschriftliche) Lösung für das Problem:
Dieser Code kann so ausgeführt werden, wie er ist, da alle Anmerkungen No-Ops verwenden und von
{und übersprungen werden}.Die Grundidee ist:
1s lesen , erhöhen Sie dieses Element.Wenn wir a lesen
0, machen Sie eine Bereinigung. Wenn die resultierende Ganzzahl größer als Null war, kehren Sie zu 1 zurück.Jetzt haben wir eine Liste der Eingangsnummern am Ende von Chucks Band und wir kennen die Länge der Liste.
Subtrahieren Sie 2 von der Länge der Liste (in den folgenden Schritten werden die beiden größten Elemente ignoriert). Rufen Sie dies auf
N.Erhöhen Sie
N > 0währenddessen eine laufende Summe und dekrementieren Sie dann alle Listenelemente. Immer wenn ein Listenelement Null erreicht, wird dekrementiertN.Am Ende enthält die laufende Summe die drittgrößte Zahl in der Eingabe
M.Schreiben Sie
MKopien von.bis zum Ende von Chucks Band.1auf Brians Band und führen Sie dann die.am Ende generierten aus .Als ich damit fertig war, stellte ich fest, dass ich es an einigen Stellen ziemlich stark vereinfachen konnte. Zum Beispiel
.könnte ich , anstatt den Zähler zu verfolgen und diese auf Chucks Band zu schreiben1, jedes Mal sofort einen ausdrucken , bevor ich alle Listenelemente dekrementiere. Änderungen an diesem Code vorzunehmen ist jedoch ein ziemlicher Schmerz, da er andere Änderungen über den gesamten Bereich verbreitet, sodass ich mich nicht darum gekümmert habe, die Änderung vorzunehmen.Das Interessante ist, wie man die Liste im Auge behält und wie man sie durchläuft. Sie können die Zahlen nicht einfach hintereinander auf Chucks Band speichern. Wenn Sie dann eine Bedingung für eines der Listenelemente überprüfen möchten, besteht die Gefahr, dass der Rest der Liste ausgeführt wird, der möglicherweise gültigen Code enthält. Sie wissen auch nicht, wie lang die Liste sein wird, deshalb können Sie nicht einfach etwas Platz vor Chucks Code reservieren.
Das nächste Problem ist, dass wir die Liste dekrementieren müssen,
Nwährend wir sie verarbeiten, und wir müssen an den Ort zurückkehren, an dem wir vorher waren. Aber{und}würde einfach die gesamte Liste überspringen.Also müssen wir dynamisch Code auf Chuck schreiben. Tatsächlich hat jedes Listenelement
idie Form:1ist ein Marker, den wir auf Null setzen können, um anzuzeigen, wo wir die Verarbeitung der Liste unterbrochen haben. Sein Zweck ist es zu fangen{oder}was wird nur über den Code und diei. Wir verwenden diesen Wert auch, um zu prüfen, ob wir während der Verarbeitung am Ende der Liste stehen. Wenn dies nicht der Fall ist, wird dies der Fall sein1und die Bedingung?wechselt die Steuerung zu Chuck.Code Awird verwendet, um mit dieser Situation umzugehen und die IP von Brian entsprechend zu verschieben.Wenn wir jetzt dekrementieren
i, müssen wir prüfen, obibereits Null ist. Während dies nicht der Fall ist,?wird die Steuerung erneut umgeschaltet, damit mussCode Balso umgegangen werden.quelle
HPR, geschrieben in Python 3 ( Cracked by TheNumberOne )
HPR (der Name bedeutet nichts) ist eine Sprache zum Verarbeiten von Listen mit ganzen Zahlen. Es ist minimalistisch , extrem begrenzt und frei von "künstlichen" Einschränkungen . Das Programmieren in HPR ist schmerzhaft, nicht weil Sie ein Rätsel lösen müssen, um den Interpreter davon abzuhalten, Sie anzuschreien, sondern weil es schwierig ist, ein Programm dazu zu bringen, irgendetwas Nützliches zu tun. Ich weiß nicht, ob HPR wesentlich interessanter ist, als das drittgrößte Element einer Liste zu berechnen.
Sprachspezifikation
Ein HPR-Programm wird in einer Umgebung ausgeführt , bei der es sich um einen ungeordneten, duplikationsfreien Satz nichtnegativer Ganzzahlen und Listen nichtnegativer Ganzzahlen handelt. Anfänglich enthält die Umgebung nur die Eingabeliste (der Interpreter analysiert sie für Sie). Es gibt drei Befehle und zwei "Kontrollfluss" -Operatoren, die die Umgebung ändern:
*Entfernt das erste Element jeder nicht leeren Liste in der Umgebung und platziert es in der Umgebung. Leere Listen sind nicht betroffen. Zum Beispiel verwandelt es sich-dekrementiert alle Zahlen in der Umgebung und entfernt dann negative Elemente. Zum Beispiel verwandelt es sich$Dreht jede Liste in der Umgebung um einen Schritt nach links. Zum Beispiel verwandelt es sich!(A)(B), woAundBsind Programme, ist im Grunde einewhileSchleife. Es führt die "Aktion" aus,Abis der "Test"Bzu einer leeren Umgebung führen würde. Dies kann eine Endlosschleife erzeugen.#(A)(B), woAundBsind Programme, giltAundBfür die aktuelle Umgebung und nimmt die symmetrische Differenz der Ergebnisse.Die Befehle werden von links nach rechts ausgeführt. Am Ende wird die Größe der Umgebung in Unary gedruckt.
Der Dolmetscher
Dieser Interpreter enthält den Befehl debug
?, der die Umgebung druckt, ohne sie zu ändern. Es sollte in keiner Lösung der Aufgabe vorkommen. Alle Zeichen außer*-$!#()?werden einfach ignoriert, sodass Sie Kommentare direkt in den Code schreiben können. Schließlich erkennt der Interpreter die Redewendung!(A)(#(A)())als "ausführen,Abis sich das Ergebnis nicht mehr ändert" und optimiert sie für zusätzliche Geschwindigkeit (ich brauchte sie, damit meine Lösung im letzten Testfall in weniger als einer Stunde fertig ist).Meine Lösung
Meine Referenzlösung ist 484 Byte lang, also ziemlich kurz im Vergleich zum 3271-Byte-Programm von TheNumberOne. Dies ist höchstwahrscheinlich auf das ausgeklügelte und großartige Makrosystem TheNumberOne zurückzuführen, das für die Programmierung in HPR entwickelt wurde. Die Grundidee in unseren beiden Programmen ist ähnlich:
Soweit ich das beurteilen kann, sind die genauen Implementierungsdetails jedoch sehr unterschiedlich. Hier ist meine Lösung:
Und hier ist das kommentierte Python-Programm, das es produziert (nichts Besonderes hier, nur grundlegende String-Manipulation, um alle Wiederholungen loszuwerden):
quelle
TKDYNS (Um den Drachen zu töten, brauchst du ein Schwert) - Gebrochen von Martin Büttner
EDIT: Ich habe meine Lösung und Erklärung unter dem Hauptbeitrag hinzugefügt.
Hintergrund
In dieser Sprache übernimmst du die Kontrolle über einen tapferen Krieger, der beauftragt wurde, einen schrecklichen Drachen zu töten. Der Drache lebt in einem unterirdischen Labyrinth voller Gefahren und Gefahren, und bis jetzt war niemand in der Lage, dies zu erfassen und zu überleben. Das bedeutet, dass Sie sich in völliger Dunkelheit auf den Weg zum Drachen machen müssen und dabei nur über Intuition und Mut verfügen müssen, um Sie zu führen.
...
Nicht ganz. Sie haben einen nahezu unbegrenzten Vorrat an Einweg-Dienern mitgebracht, und sie sind bereit, Ihnen vorauszugehen, um den sicheren Weg zu finden. Leider sind sie alle so dick wie zwei kurze Bretter und tun nur genau das, was Sie ihnen sagen. Es liegt an Ihnen, eine clevere Methode zu finden, um sicherzustellen, dass Ihre Schergen den richtigen Weg finden.
Noch ein paar Details
Das Versteck des Drachen hat die Form eines 10x10-Gitters. Zwischen bestimmten benachbarten Punkten im Raster befindet sich ein schmaler Gehweg. zwischen anderen gibt es eine tiefe Kluft und einen sicheren Tod. Ein Beispiellayout für ein 4x4-Raster könnte wie folgt aussehen:
Sie wissen, dass es immer einen Weg gibt, von einem Punkt zu einem anderen zu gelangen, aber nicht mehr als das wurde Ihnen offenbart.
Um den Drachen erfolgreich zu besiegen, musst du zuerst einige Gegenstände einsammeln, die du zu einer magischen Drachentötungsklinge kombinieren kannst. Praktischerweise sind alle Teile für diese Waffe in der Drachenhöhle verteilt. Sie müssen sie nur einsammeln.
Die Wendung ist, dass jedes Stück der Waffe Sprengfallen hat. Bei jeder Abholung ändert sich die Anordnung der Gehwege. Bisher sichere Wege könnten jetzt zum sicheren Tod führen und umgekehrt.
Befehle
Es gibt nur 5 gültige Befehle.
<- Machen Sie einen Schritt nach links>- Machen Sie einen Schritt nach rechts^- Machen Sie einen Schritt nach obenv- Machen Sie einen Schritt nach untenc- Sammeln Sie alle Gegenstände, die an Ihrer aktuellen Position herumliegen. Wenn Gegenstände vorhanden waren, ändert sich das Layout der Höhle. Nehmen Sie Ihre Position modulo 10, wobei die Positionen wie oben in Zeilen nummeriert sind. Der Interpreter enthält 10 fest codierte Layouts, und das Layout ändert sich in das entsprechende Layout. Wenn Sie sich beispielsweise an Position 13 befinden, ändert sich das Layout inlayouts[3]Die Layouts, wie sie im Interpeter erscheinen, wurden wie folgt in Ganzzahlen codiert:
Das leere Layout wird zu Null codiert.
Sei für jede Kante im Layout
xdie kleinere der beiden Positionen, die sie verbindet.Wenn der Schritt horizontal ist, fügen Sie
2^(2*x)die Codierung hinzu (das ist die Potenz von, nicht XOR)Wenn der Schritt vertikal ist, fügen Sie
2^(2*x + 1)der Codierung hinzu.Ausführungsablauf
Der Interpreter wird mit dem Namen einer Quelldatei als Befehlszeilenargument ausgeführt.
Wenn der Interpreter ausgeführt wird, fordert er den Benutzer auf, eine Quest einzugeben. Diese Eingabe sollte in der in der Frage beschriebenen Form erfolgen und die Positionen der Komponenten der Waffe im Versteck bestimmen. Insbesondere wird jede eingegebene Ganzzahl modulo 100 genommen und an der entsprechenden Stelle in der Höhle platziert.
Jedes Quellprogramm besteht aus mehreren Zeilen, wobei jede Zeile aus einer Folge der oben genannten 5 gültigen Zeichen besteht. Diese Linien repräsentieren Ihre Schergen. Du, der Krieger, verfolgst eine Abfolge von Aktionen, von denen bekannt ist, dass sie sicher sind. Anfangs wissen Sie nichts über die Höhle, daher ist diese Sequenz leer. Bei jedem Diener wird ab Position 0 Folgendes ausgeführt:
Der Diener wird angewiesen, alle als sicher bekannten Aktionen auszuführen, gefolgt von den Aktionen in seiner eigenen Codezeile.
Wenn der Diener zu irgendeinem Zeitpunkt stirbt, werden Sie darüber informiert und das Versteck wird auf seine ursprüngliche Konfiguration zurückgesetzt. Alle Gegenstände werden ersetzt und die Laufstege kehren in ihre Ausgangsposition zurück.
Wenn stattdessen der Diener überlebt, verdampft man ihn trotzdem - es ist schließlich nur ein Diener. Wie zuvor löst dies das Zurücksetzen des Verstecks in den Ausgangszustand aus, aber dieses Mal hängen Sie die Aktionen aus der Codezeile des Schergen an die Sequenz der als sicher bekannten Aktionen an.
Sobald alle Schergen erschöpft sind, führen Sie als Krieger alle als sicher bekannten Aktionen aus, und zwar wieder ab Position 0. Es gibt zwei mögliche Ergebnisse:
Sie sammeln alle Teile der Waffe - in diesem Fall töten Sie den Drachen erfolgreich und es wird eine aufregende Siegesbotschaft ausgegeben. Diese Siegesnachricht enthält unter anderem Zeichen,
nwobeindie dritthöchste Zahl als Eingabe angegeben wird.Sie haben einige Waffenteile nicht eingesammelt - in diesem Fall lebt der Drache weiter und Sie haben Ihre Suche nicht bestanden.
Dolmetschercode (Python 2)
Viel Glück, tapferer Krieger.
Meine Lösung und Erklärung
Hier ist ein Python-Skript, das Quellcode generiert, um das Problem zu lösen. Aus Gründen des Interesses ist Martins endgültiger Quellcode etwa fünfmal kleiner als der von meinem Skript erzeugte Code. Andererseits ist mein Skript zum Generieren des Codes ungefähr 15-mal kleiner als Martins Mathematica-Programm ...
Grundstruktur
Dadurch werden 990 Quellcodezeilen generiert, die in Gruppen zu 10 vorliegen. Die ersten 10 Zeilen enthalten Anweisungen, die versuchen, einen Diener von Position
0zu Position zu bewegen1, und dann einen Gegenstand zu sammeln - einen Satz für jedes mögliche Layout. Die nächsten 10 Zeilen enthalten alle Anweisungen, die versuchen, einen Diener von Position1zu Position zu bewegen2und dann einen Gegenstand zu sammeln. Und so weiter ... Diese Pfade werden mit derpathFunktion im Skript berechnet - es wird nur eine einfache Tiefensuche durchgeführt.Wenn wir sicherstellen können, dass in jeder Zehnergruppe genau ein Diener erfolgreich ist, haben wir das Problem gelöst.
Das Problem mit dem Ansatz
Es mag nicht immer der Fall sein, dass genau ein Diener aus der Gruppe der 10 erfolgreich ist - zum Beispiel könnte es einem Diener, der von Position
0zu Position gelangen soll,1versehentlich gelingen, sich von Position1zu Position zu bewegen2(aufgrund von Ähnlichkeiten in den Layouts), und das Fehleinschätzungen breiten sich aus und können zu Fehlern führen.Wie man es repariert
Das Update, das ich verwendet habe, war wie folgt:
Lassen Sie ihn für jeden Diener, der versucht, von Position
nzu Position zu gelangenn+1, zuerst von Positionnzu Position0(die linke obere Ecke) und wieder zurück, dann von Positionnzu Position99(die rechte untere Ecke) und wieder zurück. Diese Anweisungen können nur aus sicherer Position ausgeführt werdenn- jede andere Startposition und der Diener wird von der Kante laufen.Diese zusätzlichen Anweisungen verhindern daher, dass Schergen versehentlich an einen Ort gelangen, für den sie nicht bestimmt sind, und dies stellt sicher, dass genau ein Schergen aus jeder Gruppe von 10 erfolgreich ist. Beachten Sie, dass es nicht unbedingt der Günstling ist, von dem Sie erwarten, dass er es ist - es kann sein, dass der Günstling, der glaubt, er sei in Layout 0, erfolgreich ist, selbst wenn wir uns wirklich in Layout 7 befinden - aber auf jeden Fall die Tatsache, dass wir es haben Eine geänderte Position bedeutet, dass alle anderen Schergen in der Gruppe notwendigerweise sterben werden. Diese zusätzlichen Schritte werden von der
assert_atFunktion berechnet , und diesafe_pathFunktion gibt einen Pfad zurück, der die Verknüpfung dieser zusätzlichen Schritte mit dem normalen Pfad darstellt.quelle
Firetype, Cracked von Martin Büttner
Eine wirklich seltsame Mischung aus BF und CJam. Und wer weiß was noch! Ich bin mir ziemlich sicher, dass dies eine einfache Aufgabe sein wird, aber es hat trotzdem Spaß gemacht. Zu Ihrer Information, der Name bezieht sich auf Vermillion Fire von Final Fantasy Type-0 .
HINWEIS : Bitte verzeihen Sie mir Unklarheiten in dieser Beschreibung. Ich bin nicht der beste Schriftsteller ...: O
Martin hat das wirklich schnell geknackt! Dies war mein ursprüngliches Programm zur Lösung des Problems:
Syntax
Ein Firetype-Skript ist im Grunde eine Liste von Zeilen. Das erste Zeichen jeder Zeile ist der auszuführende Befehl. Leerzeilen sind grundsätzlich NOPs.
Semantik
Sie haben ein Array von ganzen Zahlen und einen Zeiger (denken Sie an BF). Sie können Elemente nach links und rechts verschieben oder auf das Array "schieben".
Schieben
Wenn Sie ein Element "pushen" und sich am Ende des Arrays befinden, wird ein zusätzliches Element an das Ende angehängt. Wenn Sie nicht am Ende sind, wird das nächste Element überschrieben. Unabhängig davon wird der Zeiger immer erhöht.
Befehle
_Schieben Sie eine Null auf das Array.
+Erhöhen Sie das Element am aktuellen Zeiger.
-Dekrementieren Sie das Element am aktuellen Zeiger.
*Verdoppeln Sie das Element am aktuellen Zeiger.
/Halbieren Sie das Element am aktuellen Zeiger.
%Nehmen Sie das Element am aktuellen Zeiger, springen Sie so viele Zeilen vorwärts und bewegen Sie den Zeiger nach links. Wenn der Wert negativ ist, springen Sie stattdessen zurück.
=Nehmen Sie das Element am aktuellen Zeiger und springen Sie zu dieser Zeile + 1. Wenn es sich beispielsweise um das aktuelle Element handelt
0, wird zur Zeile gesprungen1. Dadurch wird auch der Zeiger nach links bewegt.,Liest ein Zeichen von der Standardeingabe und drückt seinen ASCII-Wert.
^Nehmen Sie das Element am aktuellen Zeiger, interpretieren Sie es als ASCII-Wert für ein Zeichen und konvertieren Sie es in eine Ganzzahl. Wenn der aktuelle Wert beispielsweise
49(der ASCII-Wert von1) ist, wird das Element am aktuellen Zeiger auf die Ganzzahl gesetzt1..Schreiben Sie die aktuelle Nummer auf den Bildschirm.
!Nehmen Sie das Element am aktuellen Zeiger und wiederholen Sie die nächste Zeile so oft wie möglich. Bewegt auch den Zeiger nach links.
<Bewegen Sie den Zeiger nach links. Wenn Sie bereits am Anfang sind, wird ein Fehler ausgelöst.
>Bewegen Sie den Zeiger nach rechts. Wenn Sie bereits am Ende sind, wird ein Fehler ausgelöst.
~Wenn das aktuelle Element ungleich Null ist, ersetzen Sie es durch
0; Andernfalls ersetzen Sie es durch1.|Quadrieren Sie das aktuelle Element.
@Stellen Sie das aktuelle Element auf die Länge des Arrays ein.
`Dupliziere das aktuelle Element.
\Sortieren Sie die Elemente an und vor dem Zeiger.
#Negiere das aktuelle Element.
Der Dolmetscher
Auch bei Github erhältlich .
quelle
self.ptr-1für den Zugriff verwenden, sollten Sie wahrscheinlichself.ptr>0nicht überprüfen>=0. (Dies sollte keine gültigen Programme ungültig machen, könnte aber dazu führen, dass einige Programme versehentlich funktionieren, was nicht der=setzt den Wert aufarray() - 1, die Dokumentation sagt+1?Acc !! (sicher)
Es ist zurück ...
... und
hoffentlichdefinitiv lückenloser.Ich habe schon das Acc gelesen ! spez. Wie ist Acc !! anders?
In Übereinstimmung !!, Schleifenvariablen verlassen den Gültigkeitsbereich, wenn die Schleife beendet wird. Sie können sie nur innerhalb der Schleife verwenden. Außerhalb erhalten Sie die Fehlermeldung "Name ist nicht definiert". Abgesehen von dieser Änderung sind die Sprachen identisch.
Aussagen
Befehle werden Zeile für Zeile analysiert. Es gibt drei Arten von Befehlen:
Count <var> while <cond>Zählt
<var>von 0 bis zu einem<cond>Wert ungleich Null, was C ++ entsprichtfor(int <var>=0; <cond>; <var>++). Der Schleifenzähler kann ein beliebiger Kleinbuchstabe sein. Die Bedingung kann ein beliebiger Ausdruck sein, an dem nicht unbedingt die Schleifenvariable beteiligt ist. Die Schleife wird angehalten, wenn der Wert der Bedingung 0 wird.Für Loops sind geschweifte Klammern im K & R-Stil erforderlich (insbesondere die Stroustrup-Variante ):
Wie oben erwähnt, sind Schleifenvariablen nur innerhalb ihrer Schleifen verfügbar . Der Versuch, sie später zu referenzieren, führt zu einem Fehler.
Write <charcode>Gibt ein einzelnes Zeichen mit dem angegebenen ASCII / Unicode-Wert an stdout aus. Der Zeichencode kann ein beliebiger Ausdruck sein.
Jeder Ausdruck, der für sich alleine steht, wird ausgewertet und dem Akkumulator (der zugänglich ist als
_) zugewiesen . So ist zB3eine Anweisung, die den Akkumulator auf 3 setzt;_ + 1erhöht den Akku; und_ * Nliest ein Zeichen und multipliziert den Akku mit seinem Zeichencode.Hinweis: Der Akku ist die einzige Variable, die direkt zugewiesen werden kann. Schleifenvariablen und
Nkönnen in Berechnungen verwendet, aber nicht geändert werden.Der Akku ist anfangs 0.
Ausdrücke
Ein Ausdruck kann ganzzahlige Literale, Schleifenvariablen (
a-z)_für den Akkumulator und den speziellen Wert enthaltenN, der ein Zeichen liest und bei jeder Verwendung auf seinen Zeichencode hin bewertet. Hinweis: Dies bedeutet, dass Sie nur einen Schuss erhalten, um jedes Zeichen zu lesen. Wenn Sie das nächste Mal verwendenN, lesen Sie das nächste Mal.Betreiber sind:
+zusätzlich-Subtraktion; unäre Verneinung*Multiplikation/ganzzahlige Division%modulo^PotenzierungKlammern können verwendet werden, um die Priorität von Operationen zu erzwingen. Jedes andere Zeichen in einem Ausdruck ist ein Syntaxfehler.
Leerzeichen und Kommentare
Führende und nachfolgende Leerzeichen und Leerzeilen werden ignoriert. Leerzeichen in Schleifenköpfen müssen genau so sein wie gezeigt, mit einem Leerzeichen zwischen dem Schleifenkopf und der öffnenden geschweiften Klammer. Leerzeichen in Ausdrücken sind optional.
#beginnt einen einzeiligen Kommentar.Input-Output
Acc !! erwartet eine einzelne Zeichenzeile als Eingabe. Jedes eingegebene Zeichen kann der Reihe nach abgerufen und sein Zeichencode mit verarbeitet werden
N. Der Versuch, über das letzte Zeichen der Zeile hinauszulesen, führt zu einem Fehler. Ein Zeichen kann ausgegeben werden, indem sein Zeichencode an dieWriteAnweisung übergeben wird.Dolmetscher
Der Interpreter (geschrieben in Python 3) übersetzt Acc !! Code in Python und
execs it.Lösung
Der Untergang des ursprünglichen Acc!war Schleifenvariablen, die weiterhin außerhalb ihrer Schleifen zugänglich waren. Dies ermöglichte das Speichern von Kopien des Akkus, was die Lösung viel zu einfach machte.
Hier ohne diese Schleife Loch (sorry), haben wir nur den Speicher zum Speichern von Sachen. Um die Aufgabe zu lösen, müssen wir jedoch vier beliebig große Werte speichern. 1 Die Lösung: Verschachteln Sie ihre Bits und speichern Sie die resultierende Kombinationsnummer im Akkumulator. Zum Beispiel würde ein Akkumulatorwert von 6437 die folgenden Daten speichern (unter Verwendung des niedrigstwertigen Bits als Einzelbit-Flag):
Wir können auf jedes Bit einer beliebigen Anzahl zugreifen, indem wir den Akkumulator durch die entsprechende Potenz von 2, Mod 2, teilen. Dies ermöglicht auch das Setzen oder Umdrehen einzelner Bits.
Auf der Makroebene durchläuft der Algorithmus die unären Zahlen in der Eingabe. Es liest einen Wert in die Zahl 0 und führt dann einen Durchlauf des Blasensortierungsalgorithmus durch, um ihn im Vergleich zu den anderen drei Zahlen an der richtigen Position zu platzieren. Schließlich wird der Wert verworfen, der in der Zahl 0 verbleibt, da dies der kleinste der vier Werte ist und niemals der drittgrößte sein kann. Wenn die Schleife beendet ist, ist Nummer 1 die drittgrößte, also verwerfen wir die anderen und geben sie aus.
Der schwierigste Teil (und der Grund, warum ich in der ersten Inkarnation globale Schleifenvariablen hatte) besteht darin, zwei Zahlen zu vergleichen, um zu wissen, ob sie ausgetauscht werden müssen. Um zwei Bits zu vergleichen, können wir eine Wahrheitstabelle in einen mathematischen Ausdruck umwandeln. mein Durchbruch für Acc !! Es wurde ein Vergleichsalgorithmus gefunden, der von niederwertigen zu höherwertigen Bits überging, da es ohne globale Variablen keine Möglichkeit gibt, die Bits einer Zahl von links nach rechts zu durchlaufen. Das niedrigstwertige Bit des Akkumulators speichert ein Flag, das signalisiert, ob die beiden aktuell betrachteten Zahlen vertauscht werden sollen.
Ich vermute, dass Acc !! ist Turing-complete, aber ich bin mir nicht sicher, ob ich mich die Mühe machen will, es zu beweisen.
Hier ist meine Lösung mit Kommentaren:
1 Laut Fragenspezifikation müssen nur Werte bis zu 1 Million unterstützt werden. Ich bin froh, dass dies niemand für eine einfachere Lösung ausgenutzt hat - obwohl ich nicht ganz sicher bin, wie Sie die Vergleiche durchführen würden.
quelle
Picofuck (sicher)
Picofuck ähnelt Smallfuck . Es arbeitet mit einem Binärband, das rechts und links ungebunden ist. Es hat die folgenden Befehle:
>Bewegen Sie den Zeiger nach rechts<Bewegen Sie den Zeiger nach links. Wenn der Zeiger vom Band fällt, wird das Programm beendet.*klappe das Bit auf den Zeiger(Wenn das Bit am Zeiger ist0, springen Sie zum nächsten))nichts tun - Klammern in Picofuck sindifBlöcke, keinewhileSchleifen..Schreiben, um das Bit am Zeiger als ASCII0oder ASCII auszugeben1.,lese von stdin, bis wir auf ein0oder stoßen1, und speichere dies im Bit am Zeiger.Picofuck-Codeumbrüche - Sobald das Ende des Programms erreicht ist, wird es von Anfang an fortgesetzt.
Außerdem lässt Picofuck geschachtelte Klammern nicht zu. Klammern in einem Picofuck Programm erscheint abwechselnd muss zwischen
(und), beginnend mit(und endend mit).Dolmetscher
Geschrieben in Python 2.7
Verwendungszweck:
python picofuck.py <source_file>Lösung
Das folgende Python 2.7-Programm gibt meine Lösung aus, die hier zu finden ist
Ich kann diesen Beitrag später mit einer gründlicheren Erläuterung der Funktionsweise bearbeiten, aber es stellt sich heraus, dass Picofuck Turing-complete ist.
quelle
PQRS - Sicher! / Lösung zur Verfügung gestellt
Grundlagen
Alle implizierten Anweisungen haben vier Speicheradressenoperanden:
Wo
vist die Größe des Speichers in Quartetten.Pᵢ,Qᵢ,Rᵢ,SᵢSigniert ganze Zahlen in Ihrem Gerät nativen Größe (zB 16, 32 oder 64 Bit) , die wir als Worte beziehen.Für jedes Quartett lautet
idie implizite Operation mit der[]Bezeichnung Indirektion:Beachten Sie, dass Subleq eine Teilmenge von PQRS ist .
Subleq wurde als vollständig erwiesen, daher sollte auch PQRS vollständig sein!
Programmstruktur
PQRS definiert einen anfänglichen Header wie folgt:
H₀ H₁ H₂ H₃ist immer die erste AnweisungP₀ Q₀ R₀ S₀. müssen zur Ladezeit definiert werden.H₀H₃PQRS verfügt über eine rudimentäre E / A, die jedoch für die Herausforderung ausreicht.
H₄ H₅: Beim Programmstart werden maximalH₅ASCII-Zeichen aus der Standardeingabe eingelesen und ab Index als Wörter gespeichertH₄.H₄undH₅müssen zum Ladezeitpunkt definiert werden. Nach dem LesenH₅wird auf die Anzahl der gelesenen Zeichen (und der gespeicherten Wörter) gesetzt.H₆ H₇: Bei Programmende werden ab IndexH₆alle Bytes derH₇Wörter als ASCII-Zeichen an die Standardausgabe ausgegeben.H₆undH₇müssen definiert werden, bevor das Programm endet. Null-Bytes'\0'in der Ausgabe werden übersprungen.Beendigung
Die Kündigung erfolgt durch Setzen
Sᵢvon Grenzeni < 0oderi ≥ v.Tricks
Quartette
Pᵢ Qᵢ Rᵢ Sᵢmüssen nicht ausgerichtet oder sequentiell sein, Verzweigungen sind in Intervallen von Unterquartetten zulässig.PQRS verfügt über eine Indirektion, sodass im Gegensatz zu Subleq genügend Flexibilität zum Implementieren von Subroutinen vorhanden ist.
Code kann sich selbst ändern!
Dolmetscher
Der Interpreter ist in C geschrieben:
Um es zu benutzen, speichern Sie es als pqrs.c und kompilieren Sie:
Beispielprogramm
Echos geben bis zu 40 Zeichen ein, denen 'PQRS-' vorangestellt ist.
Speichern Sie zum Ausführen die oben genannten
echo.pqrsInformationen unter:Ausführen der Testfälle:
Alle Testfälle laufen extrem schnell ab, zB <500 ms.
Die Herausforderung
PQRS kann als stabil eingestuft werden, daher beginnt die Challenge am 31.10.2015 um 13:00 Uhr und endet am 08.11.2015 um 13:00 Uhr, jeweils in UTC.
Viel Glück!
Lösung
Die Sprache ist der in "Baby" - der weltweit ersten elektronischen Digitalmaschine mit gespeicherten Programmen - verwendeten Sprache sehr ähnlich . Auf dieser Seite befindet sich ein Programm, mit dem der höchste Faktor einer Ganzzahl in weniger als 32 Wörtern (CRT!) Speicher ermittelt werden kann!
Ich fand das Schreiben der spezifikationskonformen Lösung nicht kompatibel mit dem Betriebssystem und der Maschine, die ich verwendete (ein Linux-Ubuntu-Derivat auf etwas älterer Hardware). Es wurde nur mehr Speicher angefordert als verfügbar, und es wurde ein Core-Dump ausgeführt. Auf Betriebssystemen mit erweiterter virtueller Speicherverwaltung oder Computern mit mindestens 8 GB Arbeitsspeicher können Sie die Lösung wahrscheinlich nach Spezifikation ausführen. Ich habe beide Lösungen bereitgestellt.
Es ist sehr schwierig, PQRS direkt zu codieren , ähnlich wie Maschinensprache, vielleicht sogar Mikrocode. Stattdessen ist es einfacher, in einer Art Assemblersprache zu schreiben, als sie zu "kompilieren". Unten finden Sie eine kommentierte Assemblersprache für die für die Ausführung der Testfälle optimierte Lösung:
Analysiert die Eingabe, konvertiert Unär in Binär, sortiert die Zahlen mit den Werten in absteigender Reihenfolge und gibt schließlich den drittgrößten Wert aus, indem Binär zurück in Unär konvertiert wird.
Beachten Sie, dass
INC(Inkrement) negativ undDEC(Dekrement) positiv ist! WoL#oderL#+1wieP-oderQ-OPs verwendet wird, werden Zeiger aktualisiert: Inkrementieren, Dekrementieren, Austauschen usw. Der Assembler wurde von Hand in PQRS kompiliert, indem die Beschriftungen durch die Offsets ersetzt wurden. Nachfolgend finden Sie die für PQRS optimierte Lösung:Der obige Code kann gespeichert werden
challenge-optimized.pqrs, um die Testfälle auszuführen.Der Vollständigkeit halber sind hier die Quellenangaben aufgeführt:
Und Lösung:
Um die oben ausgeführt, müssen Sie einen Kommentar aus
#define OPTIMIZEDund fügen Sie#define PER_SPECSinpqrs.cund neu kompilieren.Dies war eine großartige Herausforderung - ich habe das mentale Training sehr genossen! Brachte mich zurück in meine alten 6502 Assembler-Tage ...
Wenn ich PQRS als "echte" Programmiersprache implementieren würde, würde ich wahrscheinlich zusätzlich zum indirekten Zugriff zusätzliche Modi für den direkten und doppelt indirekten Zugriff sowie für die relative und absolute Position hinzufügen, beide mit indirekten Zugriffsoptionen für die Verzweigung!
quelle
Zink, geknackt! von @Zgarb
Auch bei GitHub erhältlich .
Du brauchst Dart 1.12 und Pub. Einfach ausführen
pub get, um die einzige Abhängigkeit, eine Parsing-Bibliothek, herunterzuladen.Hier ist zu hoffen, dass dies länger als 30 Minuten dauert! :O
Die Sprache
Zink orientiert sich an der Neudefinition von Operatoren. Sie können alle Operatoren in der Sprache einfach neu definieren!
Die Struktur eines typischen Zinkprogramms sieht folgendermaßen aus:
Es gibt nur zwei Datentypen: Ganzzahlen und Mengen. Es gibt kein Mengenliteral, und leere Mengen sind nicht zulässig.
Ausdrücke
Folgendes sind gültige Ausdrücke in Zink:
Literale
Zink unterstützt alle normalen ganzzahligen Literale wie
1und-2.Variablen
Zink hat Variablen (wie die meisten Sprachen). Um sie zu referenzieren, verwenden Sie einfach den Namen. Wieder wie die meisten Sprachen!
Es gibt jedoch eine spezielle Variable
S, die sich wie Pyths verhältQ. Bei der ersten Verwendung wird eine Zeile aus der Standardeingabe eingelesen und als eine Reihe von Zahlen interpretiert. Zum Beispiel1234231würde die Eingabezeile in die Menge verwandelt{1, 2, 3, 4, 3, 2, 1}.WICHTIGE NOTIZ!!! In einigen Fällen wird ein Literal am Ende einer Operatorüberschreibung falsch analysiert, sodass Sie es mit Klammern umgeben müssen.
Binäre Operationen
Die folgenden binären Operationen werden unterstützt:
+:1+1.-:1-1.*:2*2./:4/2.=:3=3.Darüber hinaus wird die folgende unäre Operation unterstützt:
#:#x.Vorrang ist immer rechtsassoziativ. Sie können Klammern verwenden, um dies zu überschreiben.
Nur Gleichheit und Länge wirken auf Mengen. Wenn Sie versuchen, die Länge einer Ganzzahl zu ermitteln, erhalten Sie die Anzahl der Stellen in der Zeichenfolgendarstellung.
Setze Verständnis
Um Mengen zu manipulieren, hat Zink Mengenverständnisse. Sie sehen so aus:
Eine Klausel ist entweder eine when-Klausel oder eine sort-Klausel.
Eine when-Klausel sieht so aus
^<expression>. Der Ausdruck nach dem Caret muss eine ganze Zahl ergeben. Wenn Sie die when-Klausel verwenden, werden nur die Elemente in der Menge verwendet, derenexpressionWert nicht Null ist. Innerhalb des Ausdrucks wird die Variable_auf den aktuellen Index in der Menge gesetzt. Es ist ungefähr gleichbedeutend mit diesem Python:Eine Sortierklausel , die so aussieht
$<expression>, sortiert die Menge absteigend nach dem Wert von<expression>. Es ist gleich dieser Python:Hier einige Beispiele zum Verständnis:
Nehmen Sie nur die Elemente der Menge
s, die gleich 5 sind:Sortieren Sie die Menge
snach dem Wert, wenn die Elemente im Quadrat sind:Überschreibt
Mit Operator-Overrides können Sie Operatoren neu definieren. Sie sehen so aus:
oder:
Im ersten Fall können Sie einen Operator definieren, der einem anderen Operator entspricht. Zum Beispiel kann ich definieren,
+um tatsächlich zu subtrahieren über:Wenn Sie dies tun, können Sie einen Operator neu definieren, um ein magischer Operator zu sein . Es gibt zwei magische Operatoren:
joinNimmt eine Menge und eine ganze Zahl und fügt den Inhalt der Menge hinzu. Wenn Sie beispielsweise{1, 2, 3}mit verbinden4, erhalten Sie die Ganzzahl14243.cutNimmt auch eine Menge und eine ganze Zahl und partitioniert die Menge bei jedem Auftreten der ganzen Zahl. Mitcuton{1, 3, 9, 4, 3, 2}und3wird erstellt{{1}, {9, 4}, {2}}... ABER alle Einzelelementsätze werden abgeflacht, so dass das Ergebnis tatsächlich ist{1, {9, 4}, 2}.Hier ist ein Beispiel, das den
+Operator neu definiertjoin:Im letzteren Fall können Sie einen Operator für den angegebenen Ausdruck neu definieren. Als Beispiel definiert dies die Plus-Operation, um die Werte hinzuzufügen und dann 1 hinzuzufügen:
Aber was ist
+:? Sie können den Doppelpunkt:an einen Operator anhängen , um immer die integrierte Version zu verwenden. In diesem Beispiel wird die eingebaute+über+:die Zahlen zu addieren, dann fügt es ein 1 (denken Sie daran, alles ist rechtsassoziativ).Das Überschreiben des Längenoperators sieht ungefähr so aus:
Beachten Sie, dass fast alle eingebauten Operationen (außer Gleichheit) diesen Längenoperator verwenden, um die Länge der Menge zu bestimmen. Wenn Sie es so definiert haben:
Jeder Teil von Zink, der an Mengen arbeitet, außer
=an dem ersten Element der Menge, die ihm gegeben wurde.Mehrfache Überschreibungen
Sie können mehrere Operatoren überschreiben, indem Sie sie durch Kommas trennen:
Drucken
Sie können in Zink nichts direkt drucken. Das Ergebnis des folgenden Ausdrucks
inwird gedruckt. Die Werte einer Menge werden mit dem Trennzeichen verknüpft. Nehmen wir zum Beispiel Folgendes:Ist dies
exprder Fall{1, 3, {2, 4}},1324wird nach Beendigung des Programms auf dem Bildschirm gedruckt.Alles zusammen
Hier ist ein einfaches Zinkprogramm, das anscheinend hinzugefügt wird
2+2, das Ergebnis jedoch 5 ergibt:Der Dolmetscher
Das geht in
bin/zinc.dart:Und das geht in
pubspec.yaml:Beabsichtigte Lösung
quelle
joinein gemischtes Set mag{1,{3,2}}, wird es einen Fehler geben? Ich kann Dart momentan nicht installieren, daher kann ich mich nicht selbst überprüfen.dart bin/zinc.dart test.zncerhalte ich einen Syntaxfehler:'file:///D:/Development/languages/zinc/bin/zinc.dart': error: line 323 pos 41: unexpected token '?'...var input = stdin.readLineSync() ?? '';-2+#:Swenn es gegeben istS, was die beiden nachgestellten Nullen abschneidet. So hatte ich gehofft, es würde gelöst. Und^soll das Set nicht umkehren ... das war ein Bug ...Kompasssuppe ( geknackt von cardboard_box )
Dolmetscher: C ++
Die Kompasssuppe ähnelt einer Turingmaschine mit einem unendlichen zweidimensionalen Klebeband. Der wichtigste Haken ist, dass sich der Anweisungsspeicher und der Datenspeicher im selben Bereich befinden und die Ausgabe des Programms den gesamten Inhalt dieses Bereichs enthält.
Wie es funktioniert
Ein Programm ist ein zweidimensionaler Textblock. Der Programmraum beginnt mit dem gesamten Quellcode, wobei das erste Zeichen bei (0,0) steht. Der Rest des Programmraums ist unendlich und wird mit Nullzeichen (ASCII 0) initialisiert.
Es gibt zwei Zeiger, die sich im Programmraum bewegen können:
!Zeichens oder bei (0,0), wenn dies nicht vorhanden ist.x,X,y, undY. Es beginnt an der Stelle des@Zeichens oder bei (0,0), wenn dies nicht vorhanden ist.Eingang
Der Inhalt von stdin wird ab dem Speicherort von in den Programmraum gedruckt
>Zeichens oder, falls nicht vorhanden, ab (0,0) .Ausgabe
Das Programm wird beendet, wenn der Ausführungszeiger unwiederbringlich außerhalb der Grenzen läuft. Die Ausgabe ist der gesamte Inhalt des Programmraums zu diesem Zeitpunkt. Es wird an stdout und 'result.txt' gesendet.
Anleitung
n- leitet den Ausführungszeiger nach Norden um (negatives y)e- leitet den Ausführungszeiger nach Osten um (positives x)s- leitet den Ausführungszeiger nach Süden um (positiv y)w- leitet den Ausführungszeiger nach Westen um (negatives x)y- bewegt den Datenzeiger nach Norden (negatives y)X- bewegt den Datenzeiger nach Osten (positives x)Y- bewegt den Datenzeiger nach Süden (positives y)x- bewegt den Datenzeiger nach Westen (negatives x)p- schreibt das nächste Zeichen, auf das der Ausführungszeiger trifft, an den Datenzeiger. Dieses Zeichen wird nicht als Anweisung ausgeführt.j- prüft das nächste Zeichen, auf das der Ausführungszeiger trifft, gegen das Zeichen unter dem Datenzeiger. Dieses Zeichen wird nicht als Anweisung ausgeführt. Wenn sie gleich sind, springt der Ausführungszeiger über das nächste Zeichen.c- schreibt das Nullzeichen an den Datenzeiger.*- breakpoint - bewirkt nur, dass der Interpreter unterbrochen wird.Alle anderen Zeichen werden vom Ausführungszeiger ignoriert.
Dolmetscher
Der Interpreter nimmt die Quelldatei als Argument und gibt sie in stdin ein. Es hat einen schrittweisen Debugger, den Sie mit einer Haltepunktanweisung im Code (
*) aufrufen können . Wenn der Ausführungszeiger beschädigt ist, wird er als ASCII 178 (Block mit dunklerer Schattierung) und der Datenzeiger als ASCII 177 (Block mit hellerer Schattierung) angezeigt.Beispiele
Hallo Welt
Katze
Parität: Akzeptiert eine Zeichenfolge, die mit einer Null ('0') abgeschlossen ist. Ausgänge
yesin der ersten Zeile des Ausgangs, wenn die Anzahl der Einsen im Eingang ungerade ist, ansonsten Ausgänge|.Tipps
Sie sollten einen guten Texteditor verwenden und die Funktionen der Taste "Einfügen" mit Bedacht nutzen. Mit der Tastenkombination "Alt-Drag" können Sie Text in mehreren Zeilen gleichzeitig hinzufügen oder löschen.
Lösung
Hier ist meine Lösung. Es ist nicht so schön wie cardboard_box's, weil ich den Quellcode selbst löschen musste. Ich hatte auch gehofft, ich könnte einen Weg finden, den gesamten Code zu löschen und nur die Antwort zu hinterlassen, aber ich konnte nicht.
Mein Ansatz war es, die verschiedenen Sequenzen von
1s auf verschiedene Zeilen aufzuteilen , sie dann so zu sortieren, dass1alle s "fallen", bis sie auf eine andere treffen1, und schließlich alles außer der dritten Zeile nach der Eingabe zu löschen.#A#liest1s und kopiert sie in die letzte Zeile des Split, bis a0gelesen wird.#B#prüft für eine Sekunde0und geht nach Norden, bis#D#es eine gibt. Andernfalls#C#beginnt eine neue Trennlinie, indem|nach der letzten eine eingefügt wird , und geht zurück zu#A#.#F#ist der Schwerkraftcode. Es geht zum letzten1der ersten Reihe und bewegt es nach oben, bis es auf1oder trifft-. Wenn es das nicht kann, markiert es die Zeile als beendet, indem es+davor setzt .#G#löscht alle nicht benötigten Splits und#H#löscht stdin und den gesamten Code zwischen den Klammern.Code:
quelle
cam Anfang ein Extra gab , das nicht hätte da sein dürfen. Ich habe es repariert. Fügte auch meine Lösung zum Problem hinzu.Acc! , Cracc'd von ppperry
Diese Sprache hat eine Schleifenstruktur, eine einfache Ganzzahl-Mathematik, Zeichen-E / A und einen Akkumulator (daher der Name). Nur einer Akku. So der Name.
Aussagen
Befehle werden Zeile für Zeile analysiert. Es gibt drei Arten von Befehlen:
Count <var> while <cond>Zählt
<var>von 0 bis zu einem<cond>Wert ungleich Null, was dem C-Stil entsprichtfor(<var>=0; <cond>; <var>++). Der Schleifenzähler kann ein beliebiger Kleinbuchstabe sein. Die Bedingung kann ein beliebiger Ausdruck sein, an dem nicht unbedingt die Schleifenvariable beteiligt ist. Die Schleife wird angehalten, wenn der Wert der Bedingung 0 wird.Für Loops sind geschweifte Klammern im K & R-Stil erforderlich (insbesondere die Stroustrup-Variante ):
Write <charcode>Gibt ein einzelnes Zeichen mit dem angegebenen ASCII / Unicode-Wert an stdout aus. Der Zeichencode kann ein beliebiger Ausdruck sein.
Jeder Ausdruck, der für sich alleine steht, wird ausgewertet und dem Akkumulator (der zugänglich ist als
_) zugewiesen . So ist zB3eine Anweisung, die den Akkumulator auf 3 setzt;_ + 1erhöht den Akku; und_ * Nliest ein Zeichen und multipliziert den Akku mit seinem Zeichencode.Hinweis: Der Akku ist die einzige Variable, die direkt zugewiesen werden kann. Schleifenvariablen und
Nkönnen in Berechnungen verwendet, aber nicht geändert werden.Der Akku ist anfangs 0.
Ausdrücke
Ein Ausdruck kann ganzzahlige Literale, Schleifenvariablen (
a-z)_für den Akkumulator und den speziellen Wert enthaltenN, der ein Zeichen liest und bei jeder Verwendung auf seinen Zeichencode hin bewertet. Hinweis: Dies bedeutet, dass Sie nur einen Schuss erhalten, um jedes Zeichen zu lesen. das nächste Mal, wenn Sie verwendenN, lesen Sie das nächste Mal.Betreiber sind:
+zusätzlich-Subtraktion; unäre Verneinung*Multiplikation/ganzzahlige Division%modulo^PotenzierungKlammern können verwendet werden, um die Priorität von Operationen zu erzwingen. Jedes andere Zeichen in einem Ausdruck ist ein Syntaxfehler.
Leerzeichen und Kommentare
Führende und nachfolgende Leerzeichen und Leerzeilen werden ignoriert. Leerzeichen in Schleifenköpfen müssen genau so sein wie gezeigt, mit einem Leerzeichen zwischen dem Schleifenkopf und der öffnenden geschweiften Klammer. Leerzeichen in Ausdrücken sind optional.
#beginnt einen einzeiligen Kommentar.Input-Output
Acc! erwartet eine einzelne Zeichenzeile als Eingabe. Jedes eingegebene Zeichen kann der Reihe nach abgerufen und sein Zeichencode mit verarbeitet werden
N. Der Versuch, über das letzte Zeichen der Zeile hinauszulesen, führt zu einem Fehler. Ein Zeichen kann ausgegeben werden, indem sein Zeichencode an dieWriteAnweisung übergeben wird.Dolmetscher
Der Interpreter (geschrieben in Python 3) übersetzt Acc! Code in Python und
execs it.quelle
GoToTape (sicher)
(Früher bekannt als Simp-Plex.)
Diese Sprache ist einfach. Die Hauptflusskontrolle ist goto, die natürlichste und nützlichste Form der Kontrolle.
Sprachspezifikation
Daten werden auf einem Band und in einem Akkumulator gespeichert. Es funktioniert vollständig mit vorzeichenlosen Integraten. Jedes Zeichen ist Befehl. Im Folgenden sind alle Befehle aufgeführt:
a-zsind goto Aussagen, die jeweils zuA- gehenZ.:: Stellen Sie den Akku auf den ASCII-Wert ein, der von der Eingabe mit char gekennzeichnet werden soll.~: gibt das Zeichen für den ASCII-Wert im Akkumulator aus.&: subtrahiere eins vom Akku, wenn es 1 oder mehr ist, andernfalls addiere eins.|: füge eins zum akku hinzu.<: Setzen Sie den Datenzeiger auf 0.+: Inkrementieren der Datenzelle am Datenzeiger; Bewegen Sie den Zeiger +1.-: subtrahiere eins von der Datenzelle am Datenzeiger, wenn es positiv ist; Bewegen Sie den Zeiger +1.[...]: Code n-mal ausführen, wobei n die Nummer auf dem Band am Datenzeiger ist (nicht verschachtelbar)./: Nächste Anweisung überspringen, wenn der Akku 0 ist.Dolmetscher (C ++)
Habe Spaß!
Lösung
A:+&&&&&&&&&&/gbG&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&/a<aB<[|]C[&]-[|]/c<[|]D[&]-[|]/d<[|]+E[&]|||||||||||||||||||||||||||||||||||||||||||||||||~X&/x-[|]/equelle
callocstattdessennew chareine C-artige while-Schleife geschrieben, die C-artige Speicherverwaltung verwendet, die C ++ - Datei bei jeder Codeänderung neu kompiliert und 20 ifs anstelle von a verwendet habenswitch? Ich beschwere mich nicht, aber meine Augen bluten gerade ...: Ostr.c_str()an, um eine zu bekommenchar*.Dies war eine schlechte Idee, da fast alle esoterischen Sprachen unleserlich aussehen (siehe Jelly).
Aber hier geht es:
Pylongolf2 beta6
Auf den Stapel schieben
Das Verschieben in den Stapel verhält sich anders als in anderen Sprachen.
Der Code
78drückt7und8in den Stapel, aber in Pylongolf drückt er78.In Pylongolf2 ist dies umschaltbar mit
Ü.Befehle
String-Verkettung und Entfernen eines Regex-Musters aus einem String
Das Symbol + verkettet Zeichenfolgen.
Sie können das Symbol - verwenden, um Zeichen nach einem regulären Muster aus einer Zeichenfolge zu entfernen:
Dieser Code nimmt Eingaben vor und entfernt alle nicht alphabetischen Zeichen, indem alle übereinstimmenden Muster entfernt werden
[^a-zA-Z].Das ausgewählte Element muss der reguläre Ausdruck und das vorherige Element die zu bearbeitende Zeichenfolge sein.
If-Anweisungen
Wenn Sie if-Anweisungen ausführen möchten, setzen Sie ein
=, um das ausgewählte und das nachfolgende Element zu vergleichen.Dies platziert entweder ein
trueoder einfalsein seinem Platz.Der Befehl
?überprüft diesen Booleschen Wert.Wenn es
trueso ist, tut es nichts und der Dolmetscher geht weiter.Wenn es
falseder Fall, springt der Interpreter zum nächsten¿Zeichen.Aus der Github-Seite entnommen.
Dolmetscher für Pylongolf2 (Java):
quelle
Regenbogen (Hinweis: Dolmetscher in Kürze)
Ich weiß, dass diese Herausforderung abgelaufen ist.
Regenbogen ist eine Mischung aus ... vielen Dingen.
Rainbow ist eine auf 2D-Stacks basierende Sprache mit zwei Stacks (Like Brain-Flak) und 8 Richtungen (
N NE E SE S SW W NW). Es gibt 8 Befehle:1,+,*,"Tut genau das, was sie in 1+ tun.!Schaltet den aktiven Stapel um.>IP im Uhrzeigersinn drehen.,Geben Sie ein Zeichen ein und drücken Sie es..Pop und Ausgabe eines Zeichens.Zeichen im Quellcode werden jedoch nicht sofort ausgeführt. Stattdessen
[The Character in the source code]^[Top Of Stack]wird in das Collatz Conjecture-Objekt eingespeist, und die Anzahl der Schritte, die erforderlich sind, um 1 zu erreichen, wird durch die ASCII-Tabelle in ein Zeichen umgewandelt. Dieses Zeichen wird dann ausgeführt.Zu Beginn des Programms wird der Quellcode (mit Ausnahme des letzten Zeichens) auf den Stapel geschoben.
Wenn die IP den Rand des Quellcodes erreicht, wird sie beendet.
Apokalypse
n und m sind zwei Register. Wenn ein
>Befehl ausgeführt wird, wird m inkrementiert. Apokalypse wird nur ausgelöst, wenn m n überschreitet. Wenn Apokalypse passiert, ist es:m ist anfänglich Null und n ist anfänglich das letzte Zeichen des Quellcodes.
Verschlüsselung
Nach dem Ausführen einer Ausführung wird der Quellcode verschlüsselt. Der ASCII-Wert des ersten Zeichens wird um eins erhöht, der zweite um eins verringert, der dritte um zwei erhöht, der vierte um zwei verringert usw.
quelle