Ich habe kürzlich eine Hausaufgabe gemacht, bei der ich ein Modell für die 10-stellige MNIST-Klassifizierung lernen musste. Die HW hatte einen Gerüstcode und ich sollte im Kontext dieses Codes arbeiten.
Meine Hausaufgaben funktionieren / bestehen Tests, aber jetzt versuche ich, alles von Grund auf neu zu machen (mein eigenes nn-Framework, kein hw-Gerüstcode), und ich bin festgefahren, den Grandient von softmax im Backprop-Schritt anzuwenden, und denke sogar darüber nach, was das hw ist Der Gerüstcode ist möglicherweise nicht korrekt.
Das hw lässt mich das, was sie "Softmax-Verlust" nennen, als letzten Knoten im nn verwenden. Aus irgendeinem Grund haben sie beschlossen, eine Softmax-Aktivierung mit dem Kreuzentropieverlust in einem zu verbinden, anstatt Softmax als Aktivierungsfunktion und Kreuzentropie als separate Verlustfunktion zu behandeln.
Die hw loss func sieht dann so aus (von mir minimal bearbeitet):
class SoftmaxLoss:
"""
A batched softmax loss, used for classification problems.
input[0] (the prediction) = np.array of dims batch_size x 10
input[1] (the truth) = np.array of dims batch_size x 10
"""
@staticmethod
def softmax(input):
exp = np.exp(input - np.max(input, axis=1, keepdims=True))
return exp / np.sum(exp, axis=1, keepdims=True)
@staticmethod
def forward(inputs):
softmax = SoftmaxLoss.softmax(inputs[0])
labels = inputs[1]
return np.mean(-np.sum(labels * np.log(softmax), axis=1))
@staticmethod
def backward(inputs, gradient):
softmax = SoftmaxLoss.softmax(inputs[0])
return [
gradient * (softmax - inputs[1]) / inputs[0].shape[0],
gradient * (-np.log(softmax)) / inputs[0].shape[0]
]
Wie Sie sehen können, macht es vorwärts vorwärts softmax (x) und kreuzt dann den Entropieverlust.
Aber auf Backprop scheint es nur die Ableitung der Kreuzentropie und nicht der Softmax zu tun. Softmax bleibt als solches erhalten.
Sollte es nicht auch die Ableitung von Softmax in Bezug auf die Eingabe in Softmax nehmen?
Unter der Annahme, dass es die Ableitung von Softmax nehmen sollte, bin ich mir nicht sicher, wie diese Hardware die Tests tatsächlich besteht ...
Jetzt habe ich in meiner eigenen Implementierung von Grund auf Softmax- und Cross-Entropy-Knoten wie folgt getrennt (p und t stehen für vorhergesagt und Wahrheit):
class SoftMax(NetNode):
def __init__(self, x):
ex = np.exp(x.data - np.max(x.data, axis=1, keepdims=True))
super().__init__(ex / np.sum(ex, axis=1, keepdims=True), x)
def _back(self, x):
g = self.data * (np.eye(self.data.shape[0]) - self.data)
x.g += self.g * g
super()._back()
class LCE(NetNode):
def __init__(self, p, t):
super().__init__(
np.mean(-np.sum(t.data * np.log(p.data), axis=1)),
p, t
)
def _back(self, p, t):
p.g += self.g * (p.data - t.data) / t.data.shape[0]
t.g += self.g * -np.log(p.data) / t.data.shape[0]
super()._back()
Wie Sie sehen können, hat mein Kreuzentropieverlust (LCE) dieselbe Ableitung wie die im hw, da dies die Ableitung für den Verlust selbst ist, ohne noch in den Softmax einzusteigen.
Aber dann müsste ich immer noch die Ableitung von Softmax machen, um sie mit der Ableitung von Verlust zu verketten. Hier stecke ich fest.
Für Softmax definiert als:
Das Derivat wird normalerweise definiert als:
Ich benötige jedoch eine Ableitung, die zu einem Tensor mit der gleichen Größe wie die Eingabe in softmax führt, in diesem Fall batch_size x 10. Ich bin mir also nicht sicher, wie das oben Gesagte auf nur 10 Komponenten angewendet werden soll, da dies impliziert, dass ich würde für alle Eingaben in Bezug auf alle Ausgaben (alle Kombinationen) oder in Matrixform differenzieren.
quelle
Antworten:
Nachdem ich weiter daran gearbeitet hatte, stellte ich fest, dass:
Die Implementierung der Hausaufgaben kombiniert Softmax mit Kreuzentropieverlust als Wahlsache, während meine Wahl, Softmax als Aktivierungsfunktion getrennt zu halten, ebenfalls gültig ist.
Bei der Implementierung der Hausaufgaben fehlt tatsächlich die Ableitung von Softmax für den Backprop-Pass.
Der Gradient von Softmax in Bezug auf seine Eingaben ist tatsächlich der Teil jeder Ausgabe in Bezug auf jede Eingabe:
Also für die Vektorform (Gradientenform):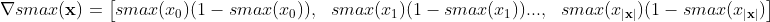
Was in meinem vektorisierten Numpy-Code einfach ist:
Wo
self.dataist der Softmax der Eingabe, der zuvor aus dem Vorwärtsdurchlauf berechnet wurde?quelle