Ich habe kürzlich die Informationen von Amazon über die AWS IoT-Plattform gelesen und bin auf einen interessanten Anwendungsbeispiel gestoßen:
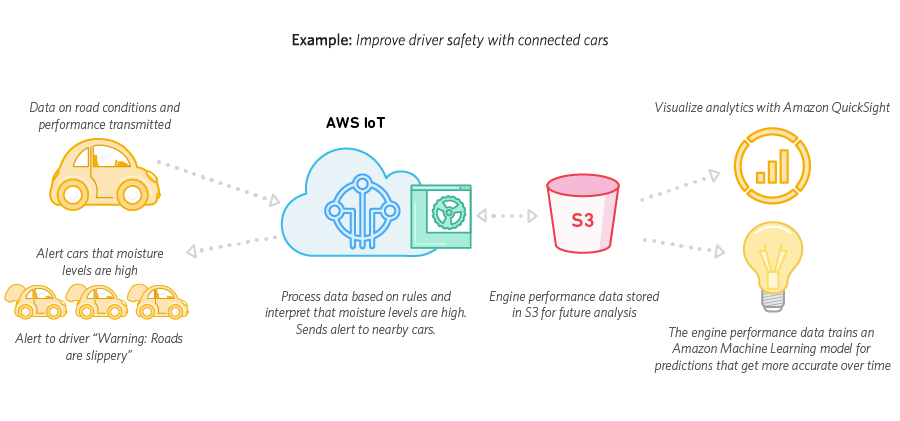
Obwohl sie nicht beschreiben, wie genau die Straßenzustandsdaten erfasst werden , warum sollte Amazon vorschlagen, die Daten an die Cloud zu senden , wenn der Sensor eine nasse Straße erkennen kann ? Wäre es nicht einfacher, die Sensordaten im Fahrzeug direkt zu verarbeiten und den Fahrer zu alarmieren, als zu erfassen, Daten an die Cloud zu senden, auf die Verarbeitung zu warten, Daten zu empfangen und dann den Fahrer zu alarmieren? Ich kann nur die möglichen Analysedaten sehen, die Sie gewinnen würden.
Ist der Beispielanwendungsfall von Amazon nur dann von Vorteil, wenn Sie Analysedaten abrufen möchten, oder gibt es andere Gründe, aus denen die Verwendung der Cloud vorgeschlagen wird?
Ich vermute, einer der Gründe ist einfach, die Leute dazu zu bringen, den Service zu nutzen, den sie verkaufen möchten, aber ich bin an technischen Gründen interessiert , falls es welche gibt.
quelle